Поисковые системы, такие как Google, имеют проблемы. Это называется «дублирующийся контент». Дублируемое содержимое означает, что аналогичный контент отображается в нескольких местах (URL-адресах) в Интернете. В результате поисковые системы не знают, какой URL-адрес должен отображаться в результатах поиска. Это может повредить ранжирование веб-страницы. Особенно, когда люди начинают связывать ее со всеми версиями контента, проблема становится еще больше. Эта статья предназначена для понимания различных причин дублирования контента и поиска решения для каждого из них.
Вы можете сравнить дублирующийся контент с перекрестком. Дорожные знаки указывают в двух разных направлениях для одного и того же конечного пункта назначения: какую дорогу вы должны выбрать? И теперь, чтобы сделать его «хуже», конечный пункт назначения тоже отличается, но только так, немного. Как читатель, вы не возражаете: вы получаете контент, к которому пришли. Поисковая система должна выбрать, какой из них показывать в результатах поиска. Конечно, она не хочет показывать один и тот же контент дважды.
Допустим, ваша статья о «ключевом слове x» появляется на http://www.example.com/keyword-x/, а то же самое содержимое также отображается на http://www.example.com/article-category/keyword-x /.
Это ситуация не настолько фиктивная: это происходит во многих современных системах управления контентом. Ваша статья была поднята несколькими блогерами. Некоторые из них ссылаются на первый URL-адрес, другие ссылаются на второй URL-адрес. Это — когда проблема поисковой системы показывает ее реальный характер: это ваша проблема.
Этот дублированный контент является вашей проблемой, потому что эти люди распространяют разные URL-адреса. Если бы все они ссылались на один и тот же URL-адрес, ваш рейтинг ранжирования для «ключевого слова x» был бы выше.
1 Причины дублирования контента
Есть десятки и десятки причин, которые вызывают дублирование контента. Большинство из них являются техническими: не так уж часто человек решает поставить один и тот же контент в двух разных местах, не выделяя оригинальный источник: для большинства из нас это кажется неестественным. Однако технические причины многочисленны. Это происходит в основном потому, что разработчики не берут во внимание, что браузер или пользователь, не говоря уже о пауке поисковых систем, думают как разработчик. Возьмем вышеупомянутый пример: http://www.example.com/keyword-x/ и http://www.example.com/article-category/keyword-x/? Если вы спросите разработчика, он скажет, что он существует только один материал.
Конечно, мы проверяем дубликат контента, а также даем вам отчет о причине дублирования контента.
1.1 Непонимание концепции URL-адреса
Разве вышеупомянутый разработчик сошел с ума? Нет, он просто говорит на другом языке. Просто весь сайт, вероятно, работает с системой баз данных. В этой базе данных есть только одна статья, программное обеспечение веб-сайта позволяет только одну и ту же статью в базе данных извлекать по нескольким URL-адресам. Это потому, что в глазах разработчика уникальный идентификатор для этой статьи — это идентификатор, который имеет эта статья в базе данных, а не URL-адрес. Однако для поисковой системы URL-адрес является уникальным идентификатором части контента. Если вы объясните это разработчику, он начнет понимать эту проблему. И после прочтения этой статьи вы сможете сразу же предоставить ему решение.
1.2 Идентификаторы сеансов
Вы часто хотите отслеживать своих посетителей и позволять, например, хранить предметы, которые они хотят купить в корзине покупок. Для этого вам нужно дать им «сеанс». Сессия — это в основном краткая история того, что посетитель сделал на вашем сайте, и может содержать такие вещи, как предметы в корзине покупок. Чтобы поддерживать этот сеанс, в то время как посетитель кликает с одной страницы на другую, то уникальный идентификатор для этого сеанса нужно где-то хранить. Наиболее распространенным решением является использование файлов cookie. Однако поисковые системы обычно не хранят файлы cookie.
В этом случае некоторые системы возвращаются к использованию идентификаторов сеанса в URL-адресе. Это означает, что каждая внутренняя ссылка на веб-сайте получает этот идентификатор сеанса, присоединенный к URL-адресу, и поскольку этот идентификатор сеанса уникален для этого сеанса, он создает новый URL-адрес и, таким образом, дублирует контент.
1.3 Параметры URL, используемые для отслеживания и сортировки
Другой причиной дублирования контента является использование параметров URL, которые не изменяют содержимое страницы, например, в ссылках на отслеживание. Вы видите, http://www.example.com/keyword-x/ и http://www.example.com/keyword-x/?source=rss не являются фактически одним и тем же URL-адресом для поисковой системы. Последний может позволить вам отслеживать, из каких источников люди пришли, но это может также затруднить вам ранжирование. Очень нежелательный побочный эффект!
Конечно, это справедливо не только для поиска параметров отслеживания, но и для каждого параметра, который вы можете добавить к URL-адресу, но который не изменяет жизненно важную часть контента. Является ли этот параметр для «изменения сортировки по набору продуктов» или для «отображения другой боковой панели»: все они вызывают дублирование контента.
1.4 «Скребки» и синдикация контента

Большинство причин дублирования контента — это все ваши собственные ошибки или, по крайней мере, «ошибки» вашего веб-сайта. Иногда другие веб-сайты используют ваш контент с вашего согласия или без такового. Они не всегда ссылаются на вашу оригинальную статью, и поэтому поисковая система не «получает» ее и имеет дело с еще одной версией той же статьи. Чем популярнее ваш сайт, тем больше «скребков» вы будете иметь у себя, делая эту проблему больше и больше.
1.5 Порядок параметров
Другой распространенной причиной является то, что CMS не использует красивые и чистые URL-адреса, а скорее URL-адреса, такие как /? Id = 1 & cat = 2, где идентификатор относится к статье, а cat относится к категории. URL /? Cat = 2 & id = 1 будет показывать одни и те же результаты в большинстве систем веб-сайтов, но они фактически совершенно разные для поисковой системы.
1.6 Комментирование разбивки на страницы
В моем любимом WordPress, и в некоторых других системах, есть возможность разбивать ваши комментарии на страницы. Это приводит к дублированию содержимого по URL-адресу статьи, а также URL-адреса статьи + / comment-page-1 /, / comment-page-2 / и т. д.
1.7 Версия для печати
Если ваша система управления контентом создает страницы для печати, и вы связываете их со страницей своей статьи, в большинстве случаев Google найдет их, если только вы их не заблокируете. Теперь какую версию Google должен показывать? Ту, которая загружена рекламой и периферийным контентом, или только с вашей статьей?
1.8 С WWW или без WWW
Один из старейших нюансов, но иногда поисковые системы все еще ошибаются: WWW и не-WWW дублированный контент, когда доступны обе версии вашего сайта. Менее распространенная ситуация, но я тоже видел: http vs https дублирует контент, где один и тот же контент передается обоим доменам.
2 Концептуальное решение: «канонический» URL-адрес
Как было указано выше, проблема, что несколько URL-адресов приводят к одному и тому же контенту, является проблемой, но ее можно решить. Человек, работающий над публикацией, как правило, может легко рассказать вам, какой должен быть «правильный» URL для определенной статьи. Самое забавное, что иногда, когда вы спрашиваете трех человек в одной компании, они дадут три разных ответа …
Это проблема, которая нуждается в решении, потому что в конце концов может быть только один (URL). Этот «правильный» URL-адрес для части контента был назван каноническим URL-адресом поисковыми системами.
Ироническое примечание
Канонический — это термин, вытекающий из римско-католической традиции, где список священных книг был создан и принят как подлинный. Они были названы каноническими Евангелиями Нового Завета. Ирония заключается в том, что римско-католической церкви потребовалось около 300 лет и многочисленных боев, чтобы придумать этот канонический список, и в итоге они выбрали 4 версии одной и той же истории …

3 Определение проблем с дублирующимся содержимым
Возможно, вы не знаете, есть ли у вас проблема с дублирующимся содержимым на вашем сайте или с вашим контентом. Позвольте мне дать вам несколько способов узнать это.
3.1 Инструменты Google для веб-мастеров
Инструменты Google для веб-мастеров — отличный инструмент для идентификации повторяющегося контента. Если вы перейдете в Инструменты Google для веб-мастеров для своего сайта, просмотрите в разделе «Поиск внешнего вида» HTML Улучшения, и вы увидите следующее:
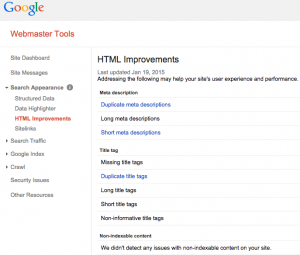
Если страницы имеют повторяющиеся заголовки или дубликаты описаний, это почти никогда не бывает хорошо. Нажав на нее, вы увидите URL-адреса, которые имеют дублирующие заголовки или описания, и помогут вам определить проблему. Проблема в том, что если у вас есть статья, похожая на статью о ключевом слове X, и она отображается в двух категориях, названия могут отличаться. Например, они могут быть «Ключевое слово X — Категория X — Пример сайта» и «Ключевое слово X — Категория Y — Пример сайта». Google не будет выбирать их как дубликаты, но вы можете найти их, выполнив поиск.
3.2 Поиск заголовков или фрагментов
Существует несколько поисковых операторов, которые очень полезны для таких случаев. Если вы хотите найти все URL-адреса вашего сайта, содержащие статью ключевого слова X, введите в Google следующую поисковую фразу:
Site: example.com intitle: «Ключевое слово X»
Затем Google покажет вам все страницы на example.com, которые содержат это ключевое слово. Чем внимательнее вы делаете эту часть, тем проще вырезать дублированный контент. Вы можете использовать тот же метод для идентификации повторяющегося содержимого в Интернете. Скажем, полное название вашей статьи было «Ключевое слово X — почему это потрясающе», вы бы искали:
Intitle: «Ключевое слово X — почему это потрясающе»
И Google предоставит вам все сайты, которые соответствуют этому названию. Иногда стоит даже искать одно или два полных предложения из вашей статьи, так как некоторые «скребки» могут изменить заголовок. В некоторых случаях, когда вы выполняете подобный поиск, Google может отображать такое уведомление на последней странице результатов:
![]()
Это признак того, что Google уже «обнуляет» результаты. Это все еще не очень хорошо, поэтому стоит щелкнуть ссылку и посмотреть на все другие результаты, чтобы узнать, можете ли вы исправить некоторые из них.
4 Практические решения для дублирования контента
После того, как вы определили, какой URL-адрес является каноническим URL-адресом для вашего контента, вам нужно начать процесс канонизации (да, я знаю, попробуйте сказать, это три раза громко и быстро). Это в основном означает, что мы должны сообщить поисковой системе о канонической версии страницы и позволить ей найти ее как можно скорее. Существует четыре метода решения проблемы в порядке предпочтения:
- Не создавать дубликаты контента
- Перенаправление дублированного содержимого на канонический URL-адрес
- Добавление канонического элемента ссылки на дублируемую страницу
- Добавление HTML-ссылки с дублированной страницы на каноническую страницу
4.1. Предотвращение дублирования содержимого
Некоторые из вышеперечисленных причин для дублированного контента имеют для них очень простые исправления:
Идентификаторы сеанса в ваших URL-адресах?
Их часто можно просто отключить в настройках вашей системы CMS.
У вас есть дублирующие страницы для печати?
Это совершенно не нужно: вы должны просто использовать таблицу стилей для печати (спросите своего веб дизайнера).
Используются разбивки на страницы в WordPress?
Вы должны просто отключить эту функцию (в разделе настроек) для обсуждения на 99% сайтов.
Параметры в другом порядке?
Попросите программиста создать сценарий, чтобы всегда заказывать параметры в одном порядке (это часто называют так называемой фабрикой URL-адресов).
Проблемы с отслеживанием ссылок?
В большинстве случаев вы можете использовать отслеживание кампаний на основе хэш-тегов вместо отслеживания кампаний на основе параметров.
Проблема с WWW или без WWW?
Выберите один и придерживайтесь его, перенаправив одно к другому. Вы также можете установить предпочтение в Инструментах Google для веб-мастеров, но вам придется вести обе версии доменного имени.
Если вы не можете легко устранить свою проблему, все равно стоит предпринять все эти усилия. Цель состояла в том, чтобы предотвратить дублирование контента. Это, безусловно, лучшее решение проблемы.
4.2 301-редирект дублирующегося содержимого
В некоторых случаях невозможно полностью предотвратить использование системы для создания неправильных URL-адресов для контента, но иногда их можно перенаправить. Если это нелогично для вас (что я понимаю), имейте это в виду во время разговора с вашими разработчиками. Если вы избавитесь от некоторых проблем с дублирующимся контентом, убедитесь, что вы перенаправляете все старые URL-адреса дубликатов контента на соответствующие канонические URL-адреса.
4.3 Использование rel = «canonical» links
Иногда вы не хотите или не можете избавиться от дублированной версии статьи. Даже когда вы знаете, что это неправильный URL. Для этой конкретной проблемы поисковые системы ввели элемент канонической ссылки. Он помещается в раздел <head> вашего сайта и выглядит следующим образом:
& Lt; link rel = «canonical»
href = «http://example.com/wordpress/seo-plugin/» & gt;
В разделе href канонической ссылки вы помещаете правильный канонический URL для своей статьи. Когда поисковая система находит этот элемент ссылки, выполняет то, что является мягким 301 перенаправлением. Он передает большую часть ссылки, собранной на этой странице, на вашу каноническую страницу.
Этот процесс немного медленнее, чем 301 перенаправление, поэтому, если вы можете сделать 301 переадресацию, что было бы предпочтительнее, о чем упоминал Джон Мюллер.
4.4. Возврат к исходному контенту
Если вы не можете сделать что-либо из вышеперечисленного, возможно, из-за того, что вы не контролируете раздел <head> сайта, на котором отображается ваш контент, добавление ссылки на исходную статью поверх или ниже статьи всегда является хорошей идеей. Некоторые «скребки» будут фильтровать эту ссылку, но некоторые другие могут ее оставить. Если Google встретит несколько ссылок, указывающих на вашу статью, скоро выяснится, что это настоящая каноническая версия статьи.
5 Заключение: дублирующийся контент исправляется и должен быть исправлен
Дублируемое содержимое происходит повсеместно. Мне еще предстоит столкнуться с сайтом из более чем 1000 страниц, у которого нет хотя бы крошечной проблемы с дублирующимся содержимым. Это то, за чем вам нужно будет постоянно следить. Проблему можно устранить, и награда может быть огромна. Ваш качественный контент может взлететь в рейтинге, просто избавившись от дублированного контента на вашем сайте!